TAnoGAN
TAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks
Abstract
时间序列数据异常检测是许多应用领域的一个重要问题。最近,生成对抗网络(GAN)在图像领域的生成和异常检测方面取得了广泛的关注。本文提出了一个基于GAN的非监督学习方法——TAnoGAN用于仅有少量时间序列样本可用的异常检测问题。
Introduction
网络传感器和执行器在智能建筑、工厂、发电厂和数据中心等地方的普遍使用,以及物联网的出现,产生了大量的时间序列数据。这些数据可用于连续监测以检测异常情况。
- 异常的定义:异常是指在时间步长上的系统行为模式不符合正常行为的定义。
由于缺乏标签信息,时间序列数据中的异常检测通常被当作一种无监督机器学习任务来处理。
目前有的几类方法各有弊端:
- 线性映射方法:无法处理时间序列的非线性交互。
- 比较当前时间步系统状态值和预测的正常范围:由于系统大多都是动态的,难以定义一个正常的范围。
GAN目前在学习生成模型任务中变得越来越受欢迎,例如结合将数据映射到潜在空间的GAN用于异常检测。
本文提出了一种新的异常检测方法,使用GAN对正常时间序列数据进行建模,然后使用异常分数检测异常,该分数表示数据点偏离正常行为的程度。为了学习该异常分数,我们先将真实的时间序列映射到潜空间,然后重构数据,用真实数据和重构数据之间的loss(不太确定这里的loss表达为什么)作为异常分数。
贡献点总结:
- 提出了TAnoGan,当仅有少量的时间序列数据可用时也能进行异常检测。(一般来说,基于神经网络的模型需要设置大量的参数。因此,这些模型需要在大量的数据点上进行训练。)
- 在不同范围的46个时间序列数据集上广泛地评估了TAnoGan。
- 基于LSTM的GAN通过利用对抗性训练,在时间序列上的表现优于LSTM。
- TAnoGan比传统和神经网络模型的性能更好。
Related work
本节介绍了异常检测的相关工作
- PCA、PLS:假设数据高斯分布,并且只对有高度相关性的数据很有效。
- KNN:基于距离的方法需要异常状态的数据或知识,还需要知道异常状态的数量。
- Angle-Based Outlier Detection (ABOD) 、 Feature Bagging (FB):基于密度估计的概率模型,效果比KNN好,但是他们不考虑时序信息,所以不适合用于处理时间序列。
- AE、ED、LSTM:深度学习方法。
- AnoGan:一个在医学图像数据上检测异常的无监督模型,采用CNN作为生成器和识别器。(作者由此启发把CNN换成了能处理时间序列的LSTM,并提出了TAnoGan)
TAnoGAN
无监督异常检测的核心思想:识别数据观测值在一段时间内是否符合正态数据分布,不符合的观测值被认为是异常点。
TAnoGAN模型是由两个子块构成的:
Learning General Data Distribution:通过对抗训练学习正常数据的分布。
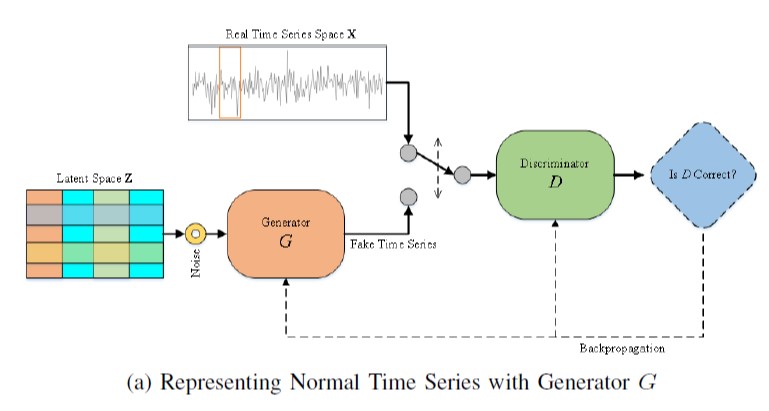
这个过程同时训练产生假时间序列数据的生成器G和学会区分产生的假数据和真实数据的鉴别器D。
为了处理时序数据,采用LSTM作为G和D的模型结构。当数据集很小的时候,一个大的鉴别器很容易对数据进行过度拟合,而一个浅的生成器不能生成足够逼真的数据来击败鉴别器。因此文章建议,当数据集很小时,使用一个简单的浅层鉴别器和一个中等深度发生器。并且,从少量的隐藏单元开始,逐步增加每一层的隐藏单元的数量,对于在小数据集上训练生成器是有效的。本文采用的G是三层LSTM结构,并且隐藏层单元分别是32,64,128;采用的D是具有100个隐藏单元的单层LSTM。
生成器:生成器的输入是从潜空间$Z$中随机采样得到得噪声向量$\mathbf{z}$。原始时间序列在送入鉴别器之前,用滑窗被划分为许多小序列$s_w$。$G(\mathbf{z},\theta_1)$也生成这些相似的小序列。
鉴别器:鉴别器$D(\mathbf{x},\theta_2)$的输入是真实数据的小序列和G生成的小序列,目的是使真实数据的概率最大化。
对抗训练:G和D进行对抗训练,直到D识别不出真实数据和G生成的数据为止。这两者之间的竞争提升了G和D的知识,直到G通过准确地学习正常的数据分布,成功地生成了现实的时间序列数据。
损失函数:最大化真实数据的概率——$D(\mathbf{x})$,并且最小化G生成的伪数据的概率——$D(G(\mathbf{z}))$:
优化器:SGD。
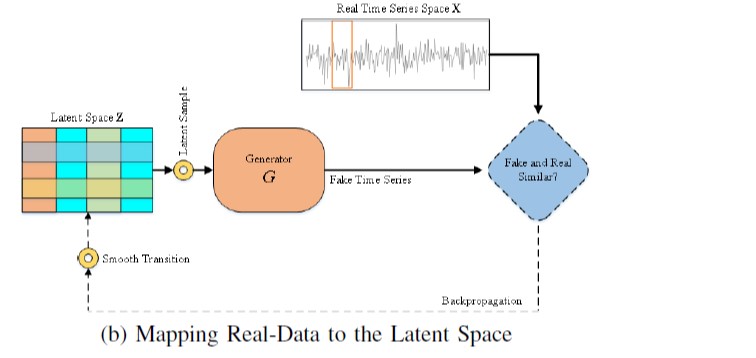
当对抗训练完成之后,我们把真实数据映射到潜空间中,作为异常检测的依据。
Mapping Real-Data to the Latent Space:把真实数据映射到潜空间。
在对抗训练中,生成器学习到了映射:$G:\mathbf{Z}->\mathbf{X}$,也就是从潜空间到正常小序列的映射$G(z)\in\mathbf{X}$。为了进行异常检测,我们需要把实时的数据$\mathbb{x}\in\mathbf{X}$映射到潜空间$\mathbb{z}\in\mathbf{Z}$中去看看对应的潜在空间产生实时序列小序列的紧密程度。但GAN没有逆映射$G^{-1}$。
对于一个给定的小序列$\mathbb{x}\in\mathbf{X}$,我们需要在潜空间中找到对应于生成的小序列$G(\mathbf{z})$和真实小序列最相似的噪声向量$\mathbf{z}\in\mathbf{Z}$。
寻找$\mathbf{z}$的方法:先随机生成一个噪声向量$\mathbf{z_1}\in\mathbf{Z}$,然后送入已经训练好的生成器去产生一个fake的小序列$G(\mathbf{z_1})$,根据提出的损失函数,进行对噪声向量$\mathbf{z_1}\in\mathbf{Z}$进行更新,产生更新后的向量,经过多次迭代和反向传播$\lambda=1,2,…\mathbf{\Lambda}$,可以找到最优的噪声向量$\mathbf{z_{\Lambda}}$。
损失函数:由residual loss和discrimination loss两部分组成,其中残差损失是用来衡量真实的小序列和用$\mathbf{z_{\lambda}}$通过训练好的生成器得到的$G(\mathbf{z}_{\lambda})$之间的point-wise的差异度。
另一部分鉴别损失,是利用丰富的鉴别器中间特征表示来估计鉴别器的损耗。其中,鉴别器中间层的输出用于构造如下损失:
总的损失函数为这两部分的加权组合:
前者强制fake小序列和真实小序列之间最相似,后者使得fake小序列在流形$\mathbf{X}$中。
异常检测
在对小序列时间序列数据进行异常检测时,目的是评估每个小序列$\mathbf{x}$是否为正常(即源自一般数据分布)或异常
(即偏离一般数据分布)观测值。在对抗训练中,生成器学习了潜空间产生正常数据的分布$p_g$,也学习了产生的以假乱真的数据分布$p_{data}$。本文提出了一个异常分数$A(\mathbf{x})$的概念,来表示对于给定的正常数据$\mathbf{x}$契合度。按下式计算:
其中,$\mathcal{D}(\mathbf{x})$是discrimination score,$\mathcal{R}(\mathbf{x})$是residual score,分别是用最后一次迭代中得到的loss,$\mathcal{L}_{R}\left(\mathbf{z}_{\lambda}\right)$和 $\mathcal{L}_{D}\left(\mathbf{z}_{\lambda}\right)$计算。
异常分数$A(\mathbf{x})$大表示异常小序列,异常分数小表示G在对抗训练中学习到的小序列符合正常数据分布。