Dynamic Graph Representation Learning via Self-Attention Networks
Abstract
以前的图表示学习方法主要关注静态图,即图结构固定不变的情形。然而,许多真实世界的图是动态的,并且会随着时间的推移而变化。在本文中提出了动态自注意网络(DySAT),用于处理动态图来学习节点特征,同时考虑图结构属性和时间演化特性。具体来说,DySAT通过在邻接节点和时间动态特性两个维度上联合使用自注意层来计算节点特征表示。我们对通信网络和双向评级网络进行了边预测实验。实验结果表明,在几种最新的图嵌入基准下,DySAT具有显著的性能提升。
Introduction
随着图表示学习的广泛发展,学习图节点的特征成为了一个基本的学习任务,其基本思想是学习每个节点的低维向量,该向量 encoder 节点及其邻域(可能还有属性)的结构特性。学习到的的特征表示有利于大量的图分析任务,如节点分类、链接预测、推荐和图可视化等。
以往对图表示学习的研究主要集中在静态图上,静态图包含一组固定的节点和边。然而,现实应用中的许多图在本质上是动态的,图结构可以随时间发展演变。图形结构的变化可以表示为一系列不同时间步长的图形快照。
例如,学术合著网络中,作者可能会定期改变他们的合作行为,电子邮件通信网络的结构可能会因为突发事件而发生巨大变化。在这种情况下,对图结构的时序演变模式进行建模,有利于准确预测节点属性和边预测任务。
与静态图的设定相比,由于复杂的时变图结构,学习动态节点特征很具有挑战性:节点和边都可以新增和消失,邻域可以合并和分离。这就要求学习到的节点特征不仅要保持节点在图结构上的靠近,同时要随着时间的推移捕捉时序相关性。
动态图结构建模问题相关工作:
使用时间规则化器来加强相邻图结构快照中节点表示的平滑性。
缺点:当节点表现出明显不同的进化行为时,方法可能会失效。
进展:在多关系知识图中使用递归神经结构进行时间推理。
缺点:时序节点特征仅限于一阶邻接节点建模,忽略了高阶图邻域的结构。
注意力机制最近在许多连续学习任务中取得了巨大的成功,如机器翻译和阅读理解,其关键是学习聚合可变大小输入的函数,同时关注与特定上下文最相关的部分。
当注意机制使用单一序列作为输入和上下文时,它通常被称为自我注意。自我注意机制也被迅速扩展到图表示学习中,使每个节点都能参与到它的邻居中,取得了静态图中半监督节点分类任务中最先进的结果。
由于动态图通常包含周期性的模式,如周期性的边或邻域,注意力机制能够利用最相关的历史信息,以促进未来的预测。
本文提出了DySAT模型来学习动态图上的节点表示。具体地说,是在结构邻域和时间动态性这两个维度上使用自我注意力机制,通过考虑其邻接节点的特征以及历史的中心节点特征为节点生成动态表示。
与静态图表示学习不同,DySAT模型可以学习动态节点表示,反映了图结构的时间演化特性。与基于时间平滑的动态图学习方法相比,DySAT能够学习到从细粒化的节点层面捕捉时序特性的注意力权重。
Problem Definition
- 动态的图结构用一系列观察到的图结构的快照来表示:$\mathbb{G}=\left\{\mathcal{G}^{1}, \ldots, \mathcal{G}^{T}\right\}$,其中$T$表示总的时间步。
- 在$t$时刻,图结构的快照可看作是一个具有共享节点集$\mathcal{V}$,共享边集$\mathcal{E}^t$,加权邻接矩阵$\boldsymbol{A}^t$的加权无向图 $\mathcal{G}_{t}=\left(\mathcal{V}, \mathcal{E}^{t}\right)$。
- 同时支持边随时间添加和删除。
- 动态图表示学习的目的是学习到每个结点$v\in\mathcal{V}$在时间步$t=1,2,…,T$上的特征表示 $e^t_v\in \mathbb{R}^d$。
- 动态节点特征表示$e^t_v$中不仅保留了邻接节点对中心节点$v$的聚合作用,也保留了时刻$t$之前的图结构演变行为。
Dynamic Self-Attention Network
在本节中,首先描述模型的高层结构。DySAT主要由结构层和时序自注意层构成,它们可用于通过层的叠加构建任意的图神经网络架构,采用multi-head注意机制来提高模型容量和稳定性。
结构模块通过自注意聚合从局部邻域提取节点特征,计算更新每个时刻图结构的中间节点特征。这些特征作为时序模块的输入,时序块处理多个时间步骤以捕获图结构的时序变化。
模型结构图如下所示:
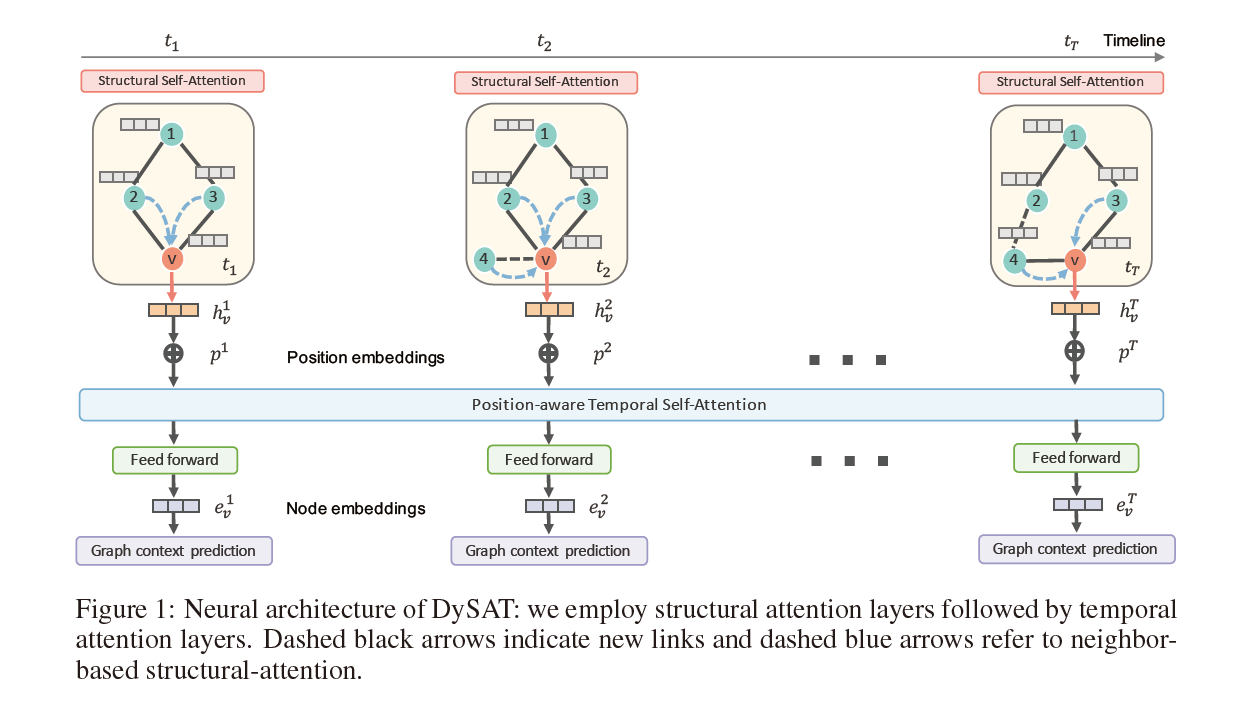
Structual Self-Attention
输入
某时刻的图结构 $\mathcal{G}\in \mathbb{G}$
输入节点的特征表示$\left\{\boldsymbol{x}_v\in\mathbb{R}^D, \forall v\in\mathcal{V} \right\}$,其中$D$是输入特征嵌入维度。
初始层的输入可以是每个节点的one-hot编码,也可以是特征。
输出
根据图结构捕获局部特性的节点新特征$\left\{\boldsymbol{z}_v\in\mathbb{R}^F, \forall v\in\mathcal{V} \right\}$,其中$F$是特征维度。
注意力机制
该层使用的注意力机制是GAT的一个变体
其中,$\mathcal{N}_v=\left\{u\in\mathcal{V}:(u,v)\in \mathcal{E}\right\}$表示中心节点的邻接节点,$\boldsymbol{W}^s\in\mathbb{R}^{D\times F}$是一个可学习的共享线性变换系数矩阵,$\boldsymbol{a}\in\mathbb{R}^{2D}$是一个可学习的权重向量,用来参数化注意力函数,||表示拼接操作,$\sigma(\cdot)$是一个非线性激活函数。与GAT不同的是,这里采用$A_{uv}$来表示边$(u,v)$的权重。
节点特征可更新如下:
在实际模型实现中,同样采用LeakyRELU非线性和ELU计算输出。实验部分采用了稀疏矩阵来实现masked self-attention。
Temporal Self-Attention
本层的关键目标是捕获图结构在多个时间步长的时间变化。
输入
特定节点$v$在不同时刻的特征序列,$\left\{\boldsymbol{x}^1_v,\boldsymbol{x}^2_v,…,\boldsymbol{x}^T_v\right\}, \boldsymbol{x}^t_v\in \mathbb{R}^{D’}$。特征序列$\boldsymbol{x}^t_v$表示了$t$时刻中心节点$v$的局部结构,$T$是总的时间步数,$D’$是输入特征的维度,把输入特征沿着时间轴拼接得到$\boldsymbol{X}_v\in\mathbb{R}^{T\times D’}$。
输出
节点$v$在每个时刻的新的特征表示,$\left\{\boldsymbol{z}^1_v,\boldsymbol{z}^2_v,…,\boldsymbol{z}^T_v\right\}, \boldsymbol{z}^t_v\in \mathbb{R}^{F’}$。把输出特征沿着时间轴拼接得到$\boldsymbol{Z}_v\in\mathbb{R}^{T\times F’}$。
注意力机制
其中,$\beta_v\in\mathbb{R}^{T\times T}$是注意力系数矩阵,$\boldsymbol{M}\in \mathbb{R}^{T\times T}$,$M_{i j} \in\{-\infty, 0\}$是掩码矩阵,并且
也就说只有之前时刻对当前时刻有影响,当$M_{ij}=-\infty$时,通过softmax函数得到的注意力系数$\beta^{ij}_v$是0。
Multi-Head Attention
Structural multi-head self-attention
Temporal multi-head self-attention
DYSAT Architecture
整个DYSAT框架从上到下分为三个模块:(1)结构注意力模块,(2)时间注意力模块,(3)图形上下文预测。
输入:时刻1到时刻$T$的图结构的数据
输出:时刻1到时刻$T$的图节点的特征表示
Structural attention block:
该模块由多个堆叠的结构自注意层组成,用于提取不同距离节点的特征。我们将每一层独立应用于具有共享参数的不同时刻的图结构,以捕获节点周围的局部邻域结构。该模块的输出节点特征为$\left\{\boldsymbol{h}_{v}^{1}, \boldsymbol{h}_{v}^{2}, \ldots, \boldsymbol{h}_{v}^{T}\right\}, \boldsymbol{h}_{v}^{t} \in \mathbb{R}^{f}$。
Temporal attention block:
用位置嵌入向量给所有时刻的图结构进行排序,$\left\{\boldsymbol{p}^{1}, \ldots, \boldsymbol{p}^{T}\right\}, \boldsymbol{p}^{t} \in \mathbb{R}^{f}$,然后将结构注意力模块的输出和位置嵌入向量进行相加:$\left\{\boldsymbol{h}_{v}^{1}+\boldsymbol{p}^{1}, \boldsymbol{h}_{v}^{2}+\boldsymbol{p}^{2}, \ldots, \boldsymbol{h}_{v}^{T}+\boldsymbol{p}^{T}\right\}$。同样采用多层堆叠的方式,并且最后一层的输出在每个位置上向前传递到前馈层,以给出最终的节点表示$\left\{\boldsymbol{e}_{v}^{1}, \boldsymbol{e}_{v}^{2}, \ldots, \boldsymbol{e}_{v}^{T},\forall v \in \mathcal{V}\right\}$。
Graph context prediction:

Experiments

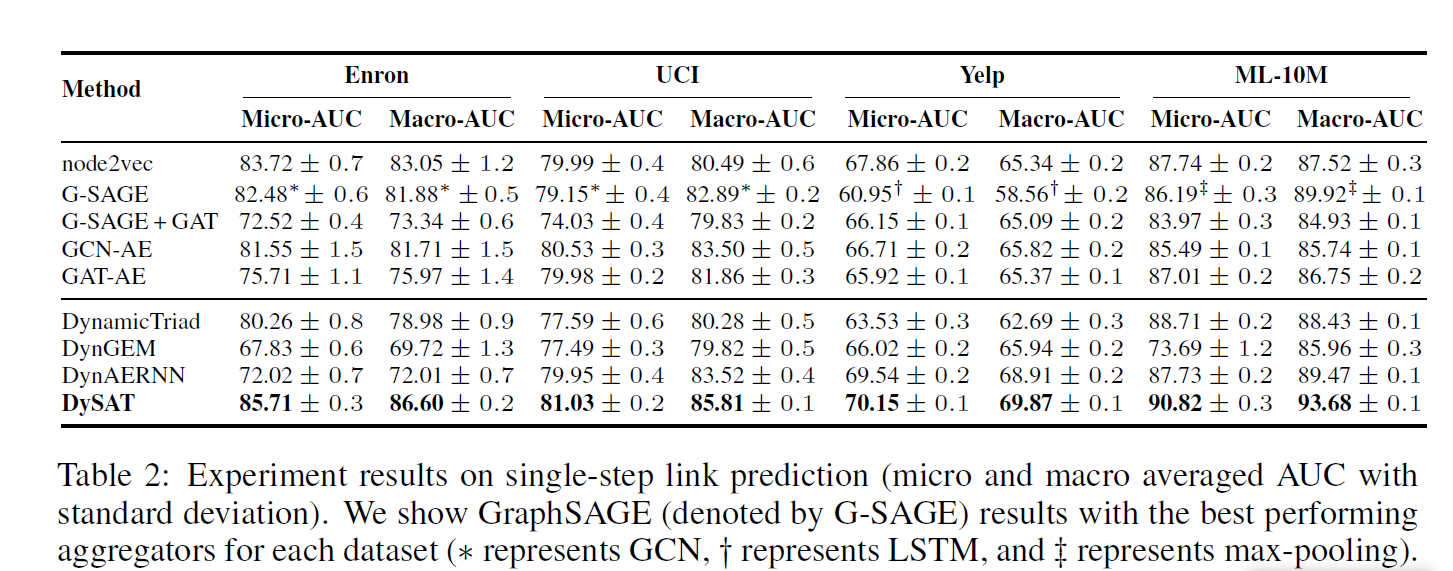
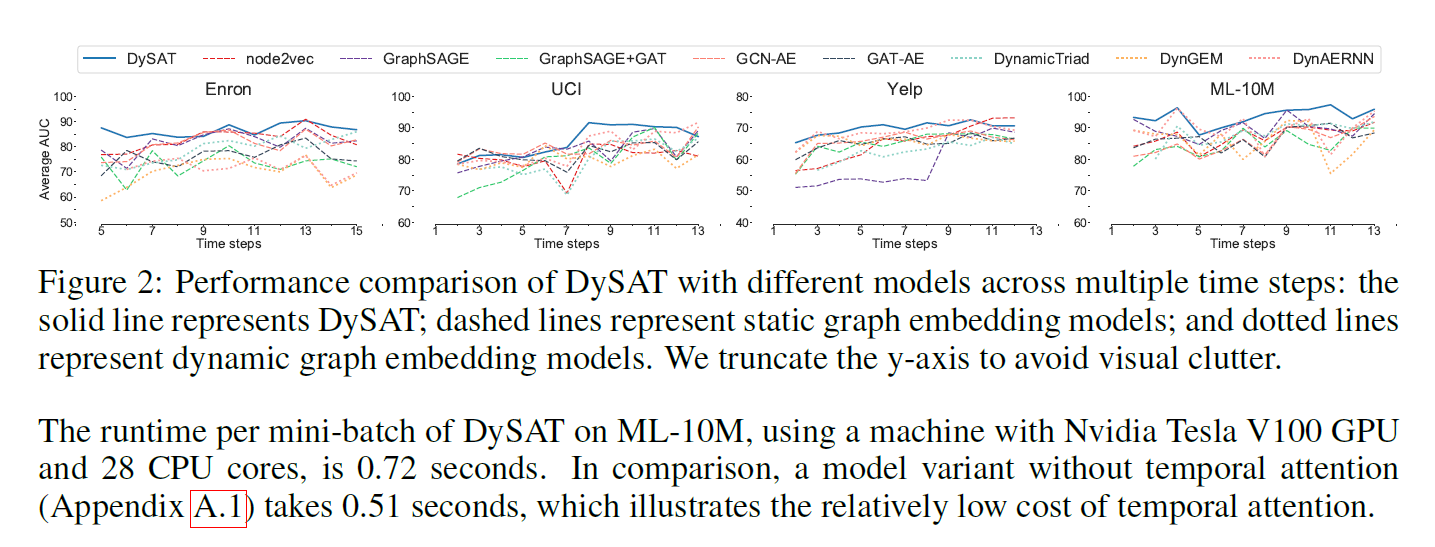
Conclusion
在本文中,我们介绍了一种新的自注意神经网络结构——DySAT。具体来说,DySAT使用(1)结构邻域和(2)历史节点表示上的自注意来计算动态节点表示,从而有效地捕捉图结构的时间进化模式。在各种真实世界动态图数据集上的实验结果表明,DySAT实现了显著的性能提高。虽然我们的实验是在没有节点特征的图上进行的,但是DySAT可以很容易地推广到特征丰富的图上。另一个有趣的方向是考虑该框架的连续时间推广,以合并更多的细粒度时间变化。