Multistep Speed Prediction on Traffic Networks
Multistep Speed Prediction on Traffic Networks-A Graph Convolutional Sequence-to-Sequence Learning Approach with Attention Mechanism
Abstract
本文为了捕获多步交通状况预测中复杂的非平稳时间动态和空间依赖性,提出了一种新的深度学习框架——attention graph convolutional sequence-to-sequence model (AGC-Seq2Seq)。在AGC-Seq2Seq中,空间和时间的依赖关系分别通过Seq2Seq模型和图卷积网络进行建模。提出了基于Seq2Seq架构的注意力机制以及新的训练方法,从而克服交通流多步预测的困难,进而能捕捉到交通模式的时间异质性(temporal heterogeneity)。
Introduction
Backgroud
技术和经济的稳定发展,使得汽车的使用在过去的几十年里有了显著的增长。然而,汽车使用的增加导致了交通拥堵、交通事故、能源过度消耗、碳排放等一系列社会问题。智能交通系统(The intelligent transportation system,ITS)被认为是一个改善交通管理和服务的有效解决方案。高精度的基于交通预测的应用不仅有利于出行者的路线规划和出发时间安排,而且能为交通控制提供有价值的信息,从而提高交通效率和安全。未来的一些研究重点有:
- 对交通网络的流量预测应该得到更多的重视;
- 采用多步法进行中长期预测更适合实际应用;
- 可结合交通流时间特性和空间特性进行研究。
Challenges
- 非平稳时变交通模式的的随机性和不确定性;
- 非欧几里得拓扑结构的数据;
- 多步预测固有的困难。
Contributions
- 同时提取时域和空域的特征,引入了注意机制以克服多步预测的挑战及捕捉城市交通模式的时间异质性;
- 设计了一种针对多步交通预测的Seq2Seq模型的训练方法,主要通过在端到端的深度学习框架中协调多维特征和时空速度变量的方法,使得测试期间的输入与训练期间一致;
- 探究了不同预测步长和路段下交通情况时间和空间变化的相关性。
Method
Preliminaries
Road Network Topology
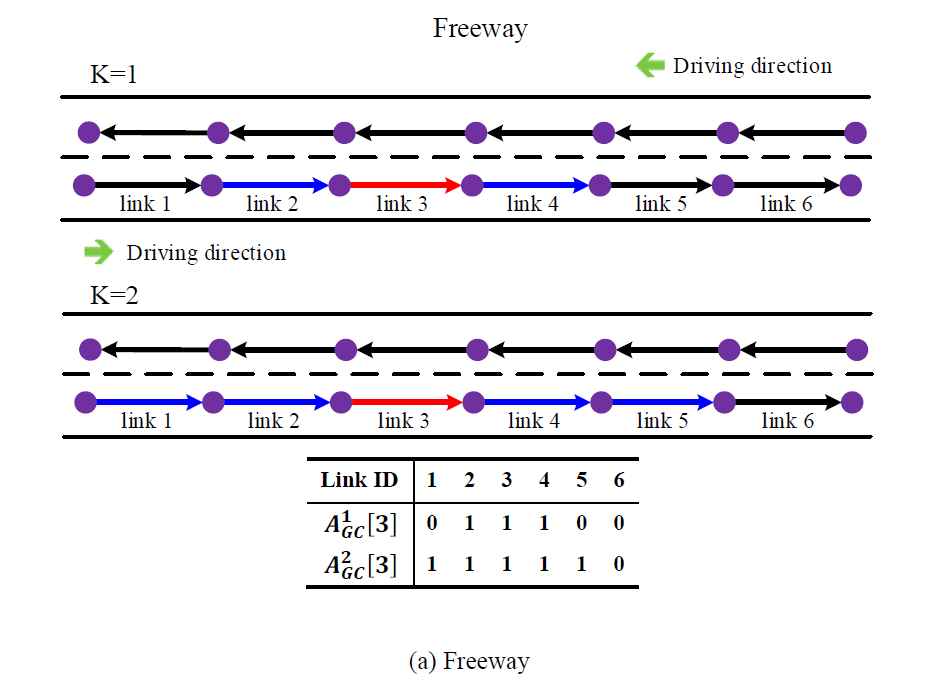
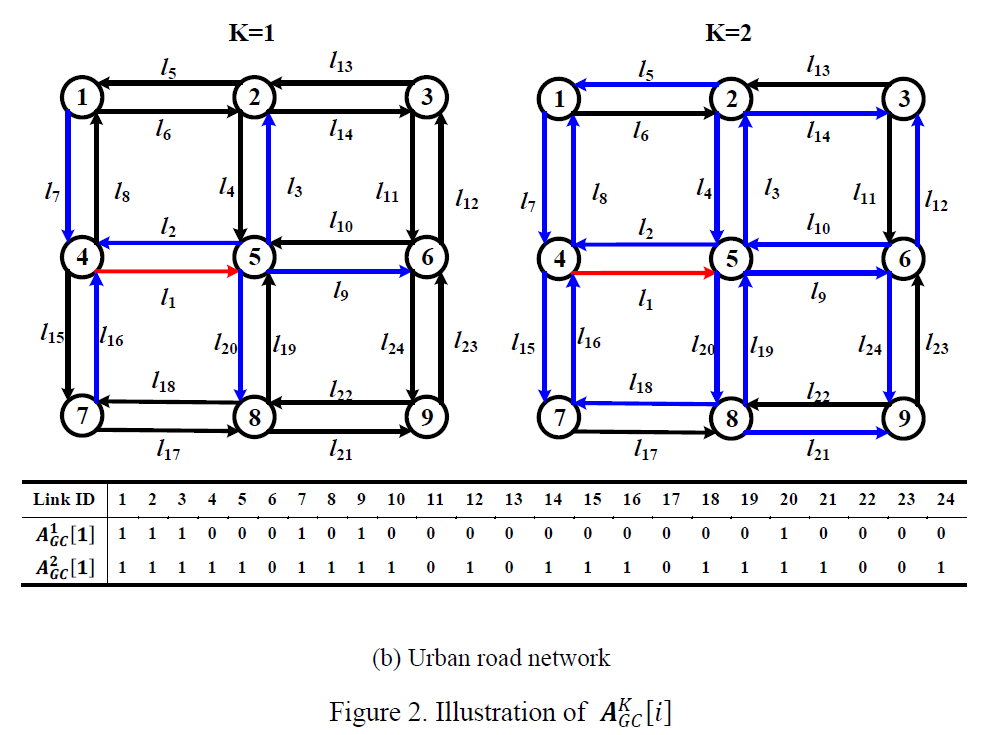
交通网数据可以用一个关于行驶方向的图$\mathcal{G}\left(\mathcal{N},\mathcal{L}\right)$来表示,其中$\mathcal{N}$表示路口,边$\mathcal{L}$表示路段。$\boldsymbol{A}$是路段的邻接矩阵,$\boldsymbol{A}\left(i,j\right)$表示路段$i$ 和路段$j$ 的相互连接关系,(值为1表示按行驶方向连接,为0则表示不连接)。网络拓扑结构如下图所示:

Traffic Speed
交通速度信息:在路段$l_i \left( \forall l_i\in\mathcal{L}\right)$ ,时间段 $t^{th}$的交通速度定义为该路段该时间间隔内浮动车辆的平均速度,记为 $v^i_t$。在时间段 $t^{th}$的交通速度定义为向量 $\boldsymbol{V}_t\in\mathfrak{R^{\left|\mathcal{L}\right|}}$,并且 $\left(\boldsymbol{V}_t\right)_i=v^i_t$。
Time-of-Day and Weekday-or-Weekend
由于将每个路段的速度汇总为5min内的平均值,因此将时间也转换为有序整数$N$,例如00:00-00:05,记为 $N_t=1$,7:00-7:05记为 $N_t =85\left(7\times 12+1\right)$ 。工作日或周末的信息用一个虚拟变量 $p_t$ 来区分。
Historical Statistic Information
通过将历史统计信息引入预测模型,可以获取交通状态的日变化趋势。历史平均速度、平均速度、最大速度、最小速度、和标准偏差在时间段$t^{th}$道路段$l_i$被定义为训练集中的平均值,中位数,最大值,最小值和标准偏差。分别记为:$v^i_{t,average}$,$v^i_{t,median}$,$v^i_{t,max}$,$v^i_t,min$ 和 $d^i_t$。
Problem Formulation
交通速度预测的任务是利用以前观测到的速度记录来预测某一时间段内各路段的未来值。多步交通速度问题可以表示为:
其中 $\hat{\boldsymbol{V}}_{t+n}$ 表示第$n$步的预测值,$\left\{\boldsymbol{V}_t,\boldsymbol{V}_{t-1},…,\boldsymbol{V}_{t-m}|m=1,2,…\right\}$ 表示相关的先前观测值向量,$\Pr\left(\cdot|\cdot\right)$ 是条件概率函数。
Graph Convolution on Traffic Networks
定义每个路段 $l_i \in \mathcal{L}$ 的邻阶接节点
$\mathcal{H_i}\left(K\right)=\left\{l_j \in\mathcal{L}|d\left(l_i,l_j\right)\leq{K}\right\}$,其中$d\left(l_i,l_j\right)$表示从$l_i$走到$l_j$需要的最小边的数量。
定义$K$阶邻接矩阵
典型邻接矩阵即1-hop邻接矩阵 $\boldsymbol{A}$,$K$阶邻接矩阵可以通过计算1-hop邻接矩阵 $\boldsymbol{A}$的$K$次幂得到,并且为了模拟拉普拉斯矩阵,使对角线元素为1,同时使拓扑图中的卷积具有自可访问性。计算公式如下:
其中,$Ci\left(\cdot\right)$使得矩阵中每个不为零的元素值为1,因此如果$l_j$属于$l_i$的$K$阶邻接节点,$l_j \in \mathcal{H}_i\left(K\right)$,或者$i=j$,则$\boldsymbol{A}^K_{GC}\left(i,j\right)=1$,否则,$\boldsymbol{A}^K_{GC}\left(i,j\right)=0$ 。
定义图卷积运算
其中,$\boldsymbol{W}_{GC}$是一个可训练的矩阵,与$\boldsymbol{A}$的大小相同。$\bigodot$表示Hadamard 乘积,实现矩阵对应元素相乘操作。
通过该乘积,会产生一个新的矩阵在$K$阶邻接位置上的可训练参数,而参数在非领域位置上的值为0。
空域离散卷积
根据上式可以发现,K阶邻接节点对应的训练参数不为0,而其余不相邻节点的训练参数为0,因此对时刻所有路段的交通速度向量$\boldsymbol{V}_t$的空域离散卷积可以通过下式实现:
因此,$\boldsymbol{V}_t\left(K\right)$称为$t$时刻的空间聚合速度向量,其中的第$i$个元素表示路段$l_i \in \mathcal{L}$在$t$时刻的空间聚合速度,它聚合了来自$K$阶邻接路段的相关信息。
上面的矩阵运算也可以通过下式一维运算来实现:
$\boldsymbol{W}_{GC}\left[i\right]$和$\boldsymbol{A}^K_{GC}\left[i\right]$是 $\boldsymbol{W}_{GC}$和$\boldsymbol{A}^K_{GC}$中的第$i$行。
对$\boldsymbol{A}^K_{GC}\left[i\right]$的理解可参照下图所示例子,其中红线表示当前路段,蓝色表示邻接路段:
(个人觉得图(b)左图,$l_{16}=1$,不知道是不是作者漏了)
AGC-Seq2Seq Model
为了捕捉时间序列特征并获得多步预测输出,我们采用Seq2Seq模型作为整个方法的基本结构。Seq2Seq模型由两个参数独立、相互连接的RNN模块组成。为了克服RNN输出时间戳固定的问题,Seq2Seq模型对编码器部分的时间序列输入进行编码以使其满足时间依赖,解码器根据 context vector 组织以时间步长排列顺序的目标输出。模型结构如下图所示:
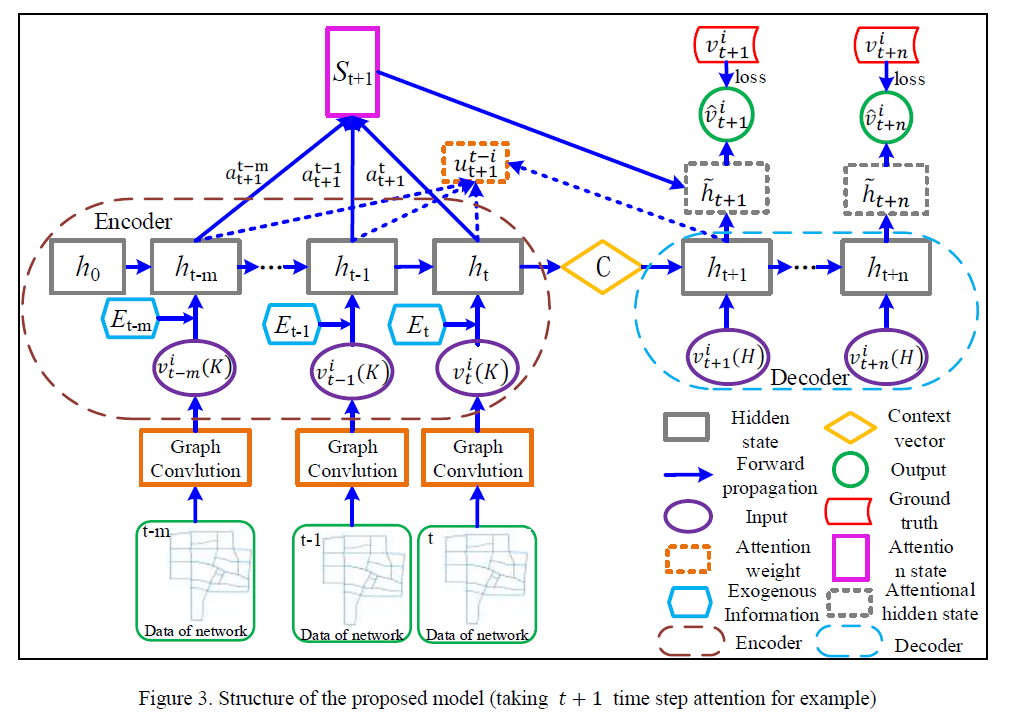
首先,使用图卷积操作来捕获各路段空间上的特性,生成spatial-temporal variable $v^i_{t-j}\left(K\right)$。
其次,与包含一天中的时段信息$N_t$,以及weekday-or-weekend信息$p_t$ 的 exogenous variable ,$\boldsymbol{E}_{t-j}$进行拼接,来构造一个输入向量,该输入向量后续将喂给Seq2Seq模型的编码器部分。
上述两步操作可通过如下公式实现:
其中,$\left[\cdot;\cdot\right]$表示将两个tensor在相同维度上进行拼接。
接着,在编码器部分,在$t-j,j\in \left\{ 0,…,m\right\} $时刻,前一个时刻的隐藏状态$\boldsymbol{h}_{t-j-1}$传递到了当前时刻,与当前时刻的输入$\boldsymbol{X}_{t-j}$一起计算当前时刻的隐藏状态$\boldsymbol{h}_{t-j}$。如图所示,context vector $\boldsymbol{C}$ 聚合了编码器中所有的信息,包括隐藏状态$\left(\boldsymbol{h}_{t-m}, \boldsymbol{h}_{t-m+1}, \cdots, \boldsymbol{h}_{t-1}\right)$,和输入$\left(\boldsymbol{X}_{t-m}, \boldsymbol{X}_{t-m+1}, \cdots, \boldsymbol{X}_{t}\right)$,作为编码器和解码器的连接者。
其中$\boldsymbol{h}_0$是初始隐藏状态,设置为零向量。$\text{Cell}_\text{encoder}(\cdot)$是由所采用的RNN结构决定的编码器的计算函数。
然后,在解码器部分,核心的想法是利用context vector $\boldsymbol{C}$作为初始隐藏状态,将输出序列一步一步进行解码。因此,在$t+j, j\in\left\{1,…,n\right\}$时刻,隐藏状态$\boldsymbol{h}_{t+j}$不仅包含输入信息,也考虑了之前时刻的输出状态 $\left(\boldsymbol{h}_{t+1},\boldsymbol{h}_{t+2},…,\boldsymbol{h}_{t+j-1}\right)$ 。
解码器的输入根据不同的训练方法确定:
Teacher forcing: 是自然语言处理中常用的一种训练策略。在该训练策略中,目标序列被输入到解码器进行训练,在测试阶段,使用之前生成的预测序列作为之后时间戳的输入。
然而,该方法不适用于时间序列问题,主要是由于解码器输入在训练周期和测试周期之间的分布不一致。
Scheduled sampling:计划抽样可用来缓解上述问题,计划抽样随机选择模板序列或之前的预测值,以某个设置好的概率大小喂给模型。
然而,该方法会增加模型复杂度,加重计算负担。
提出方法:为了克服上述问题,文章提出一种新的训练方法,使用历史统计信息和time-of-day作为输入。在时间序列预测问题中,在训练和测试阶段都可以获得历史统计信息;基于这样的事实,解码器输入在训练和测试期间的分布将会同步,从而解决了Teacher forcing的困境。此外,由于历史统计信息在多步预测中至关重要,将其加入到模型中有望提高预测精度。
解码器在$t+j$时刻的输出将通过下式计算:
在实际模型构件中,我们采用门控循环单元(GRU)作为编码器和解码器的内部结构。内部运算结构如下图所示:
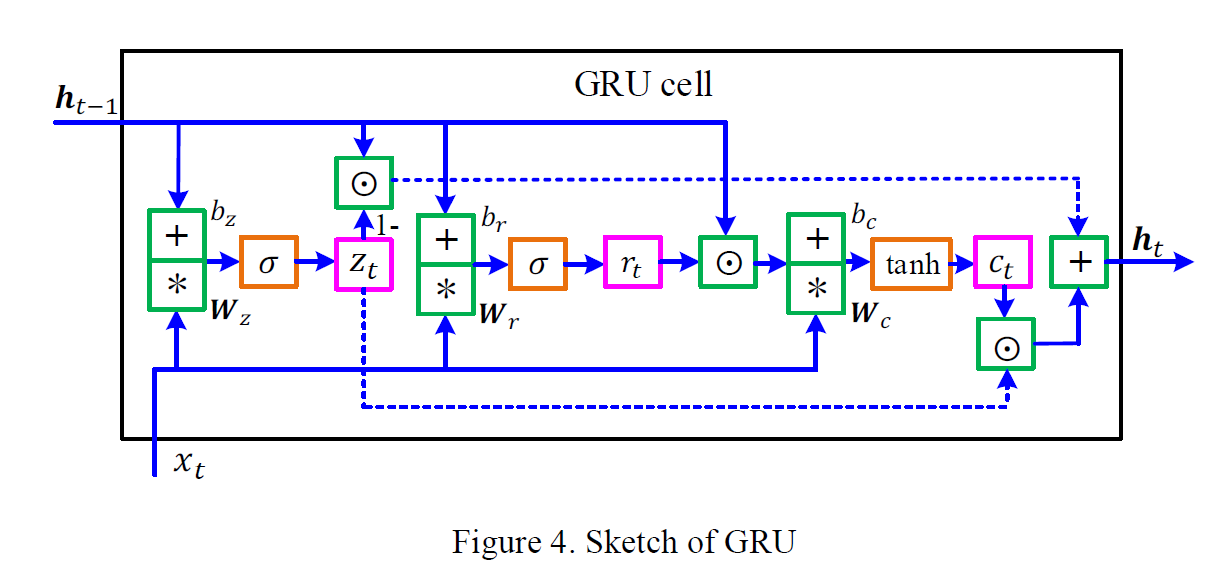
计算公式为:
加入注意力机制以捕捉交通模态中的时序异质性:关键是为每一个时间步增加一个注意力向量,用于捕捉源侧信息的相关性,以帮助预测交通速度。
在$t+j$时刻,注意力函数计算$\boldsymbol{h}_{t+j}$和一系列隐藏状态$\left(\boldsymbol{h}_{t-m}, \boldsymbol{h}_{t-m+1}, \cdots, \boldsymbol{h}_{t}\right)$之前的相似度,得到一个注意力向量$\boldsymbol{S}_{t+j}$。该注意力向量是这一系列隐藏状态的加权线性组合。加权系数及注意力向量的计算公式如下:
其中,$u_{t+j}^{t-i}$用于衡量两个隐藏状态之间的相似性,$\boldsymbol{q}^{T}$和$\boldsymbol{W}_{f}$是可训练的权重矩阵和向量。$a_{t+j}^{t-i}$ 是 $u_{t+j}^{t-i}$ 归一化后的值,进一步作为权重系数。
最终根据注意力向量$\boldsymbol{S}_{t+j}$和原始的当前隐藏状态$\boldsymbol{h}_{t+j}$,得到一个注意隐藏状态,$\boldsymbol{\tilde{h}}_{t+j}$,计算公式如下:
预测输出
最后将注意隐藏状态进行线性变换后作为预测输出:
LOSS
为了同时降低多步预测中的预测误差,我们将损失定义为$\left(\hat{v}_{t+1}, \hat{v}_{t+2}, \cdots, \hat{v}_{t+n}\right)$和$\left(v_{t+1}, v_{t+2}, \cdots, v_{t+n}\right)$之间的平均绝对误差:
在训练阶段通过小批量梯度下降算法最小化损失函数来更新所有参数。
Experiments
Dataset
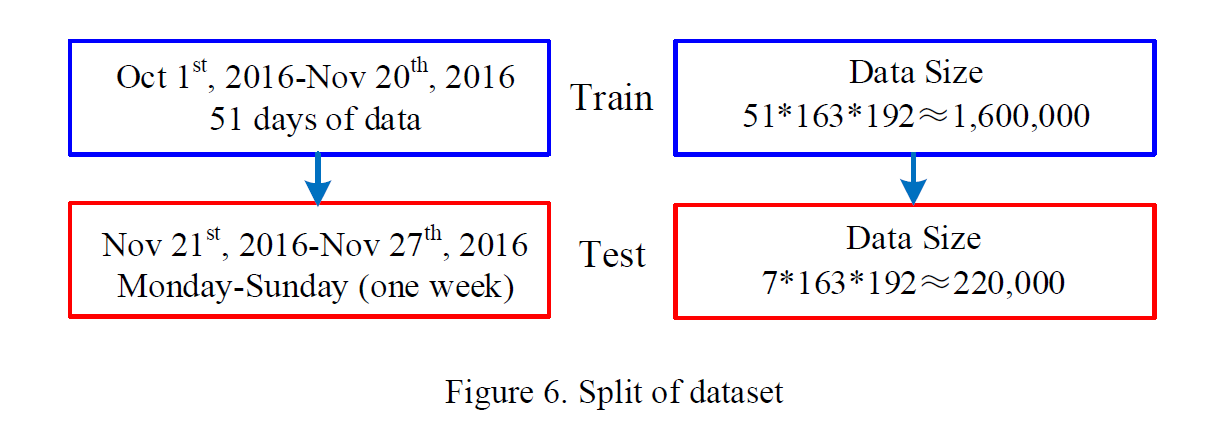
选择2018年搜狐统计的北京二环路段的交通数据进行实验验证。二环路全长33公里,我们将其分为163段,每段长200米。此外,计算每个路段的5分钟平均速度。训练和测试集分配如下:
Evaluation statistics
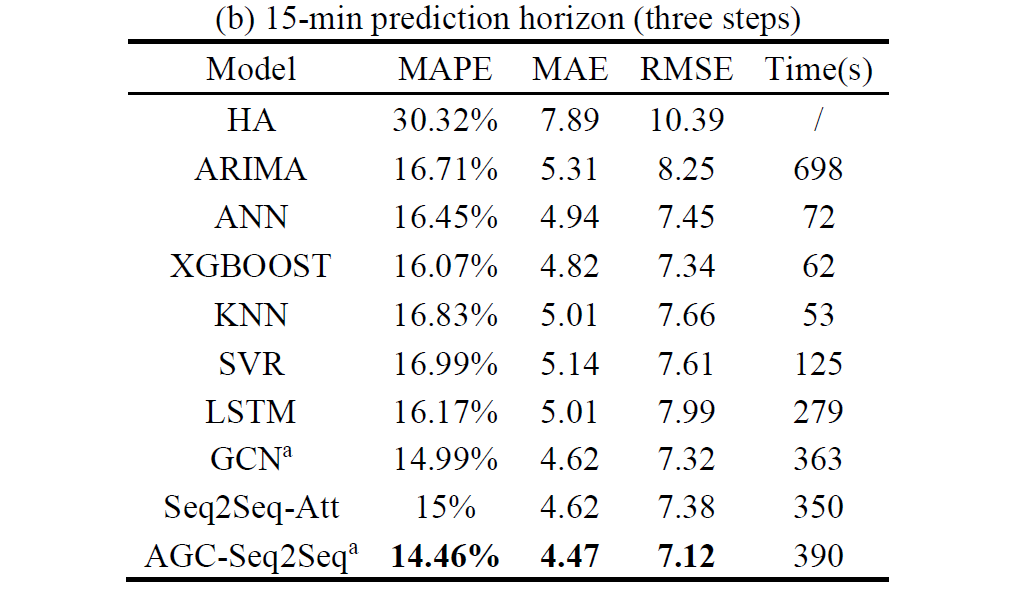
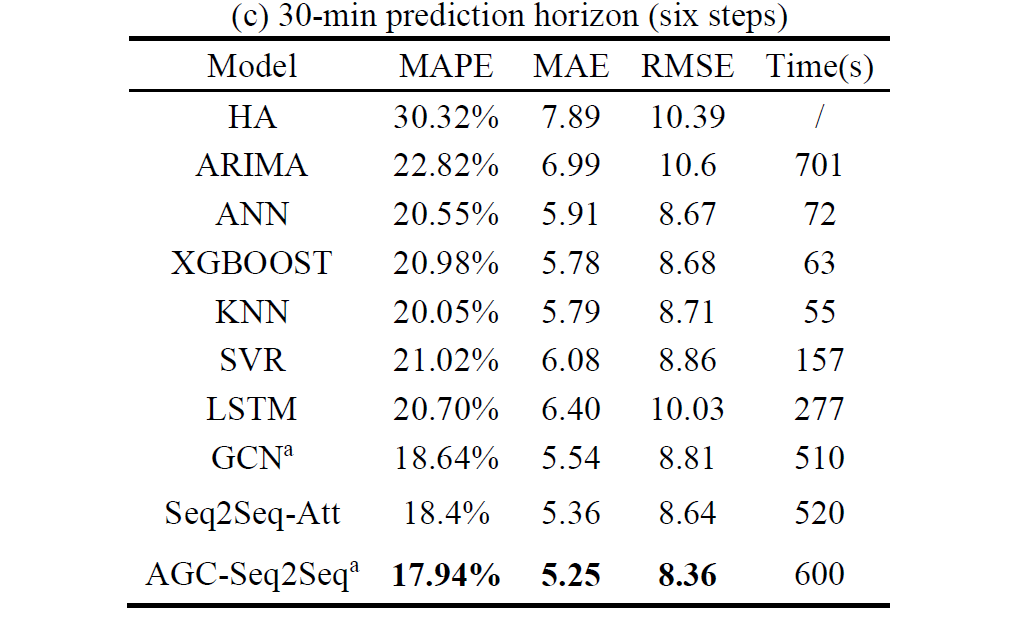
我们通过三个经典的误差指标来评估模型:
- 平均绝对百分比误差(MAPE);
- 平均绝对误差(MAE);
- 均方根误差(RMSE);
Results
AGC-Seq2Seq模型在所有预测区间内的所有指标都优于其他基准。
HA模型的表现不会随预测范围的增加而改变,因为它只依赖于历史数据。
由于交通状态在5分钟内相对稳定,所以在5分钟预测范围内所有模型的性能相似。
与传统的机器学习模型相比,深度学习方法具有更好的预测性能,但计算时间更长。
GCN(根据空间相关性建模)优于LSTM(捕捉时间特征),证明了考虑空间相关性在交通速度预测中很重要。
AGC-Seq2Seq模型相比GCN和Seq2Seq-Att有明显的改进;这强调了同时捕获时空特征对交通速度预测的重要性。但AGC-Seq2Seq模型的运行时间仅略高于GCN和 Seq2Seq-Att,这主要得益于GPU模块中先进的并行计算技术。



Conclusions
为了解决多步交通速度预测的挑战,本文致力于提出一种复杂的深度学习方法,即AGC-Seq2Seq模型。该模型结合Seq2Seq架构和图形卷积操作来学习交通网络的时空相关性。并且将注意力机制集成到模型中以捕捉交通模式的时间异质性,采用新设计的方法对整个模型结构进行训练。为了验证提出的模型的有效性,我们将其与几个基准测试模型进行比较,包括HA、ARIMA、XGBOOST、ANN, LSTM, SVR, KNN, GCN, Seq2Seq-Att。结果表明,该模型在不同预测区间下的RMSE、MAE和MAPE指标均优于基准模型。在此基础上,进一步探讨了特征的重要性、空间信息对多步预测的影响以及交通时间模式与注意系数的相关性。实验结果表明,随着预测区间的增大,过去一小时的速度特征的相对重要性和空间信息增加的效应逐渐减弱;对于交通状况变化较快的路段,过去15分钟内的回望观测值对应的注意系数值较高。
未来的研究可以包括对大型城市道路网络的实验,以及将交通流理论进一步整合到预测模型中,例如在更复杂的模型中利用交通流的传播波来确定空间邻居。从应用的角度来看,该框架可以与先进的交通管理系统集成,例如,提供系统级的实时路由服务,以减少高峰时段拥堵。