Graph Attention Networks
Abstract
本文提出了一种新的基于图结构数据的神经网络结构,通过使用masked self-attentional layers 解决图卷积网络(GCN)的一些缺点。它允许(隐式地)为邻接结点集中的不同结点分配不同的权重,并且不需要任何昂贵的矩阵操作,比如反演,也不依赖于需要预先知道图形结构。本文同时解决了GCN的几个关键挑战,并使模型适用于归纳问题(Inductive)和(Transductive)问题。GAT模型在四个benchmark数据集(Cora、Citeseer、Pubmed和proteinprotein interaction)上取得了最佳结果。
注:transductive 任务指:训练阶段与测试阶段都基于同样的图结构;inductive 任务指:训练阶段与测试阶段需要处理的图不同。通常训练阶段只是在子图(subgraph)上进行,测试阶段需要处理未知的顶点。(unseen nodes)
Introduction
图结构化数据
卷积神经网络(CNNs)已成功应用于解决图像分类、语义分割或机器翻译等问题,其中底层数据形式具有网格状结构。这种结构能够将具有可学习参数的local filter应用到所有输入位置。然而,许多有趣的任务所涉及的数据不能以网格状结构表示,而是位于一个不规则的域中,如三维网格、社交网络、电信网络、生物网络或大脑连接体。这些数据通常可以以图的形式表示。
相关前人工作
使用递归神经网络处理用有向无环图表示的图结构数据。[1,2]
使用图神经网络[3,4]直接处理更多类型的图(如循环、有向、无向图),可看作是递归神经网络的推广。它用神经网络基于节点当前的状态来产生一个输出,不断迭代此过程来更新节点的状态,直至达到平衡。Li[5]等人采用并改进了这个想法,提出在传播步骤中使用门控循环单元[6]。
卷积的推广
然而,人们对将卷积推广到图域越来越感兴趣。这方面的进展通常分为谱方法和非谱方法。
谱方法(基于图的谱表示)
进展:计算图的拉普拉斯特征分解在频域里定义卷积操作;[7]
缺点:计算复杂,并且不具有空域局部滤波器特性。
进展:进行具有平滑系数的谱滤波器的参数化;[8]
缺点:计算依然复杂
进展:通过图拉普拉斯算子的切比雪夫展开式去近似滤波器,省去了特征根分解的步骤,并具有空域局部滤波器特性;[9]
进展:通过限制过滤器在每个节点周围的一步邻域内操作,简化了图卷积网络的模型;[10]
然而,在所有上述谱方法中,学习到的滤波器依赖于拉普拉斯特征基,而拉普拉斯特征基依赖于图结构。因此,针对特定结构训练的模型不能直接应用于具有不同结构的图。
非谱方法(直接在图上定义卷积,对一组空间近邻节点进行操作)
- 挑战:如何定义一个操作能够处理不同大小的邻域,并保持CNN的权重共享性质。
- 进展:mixture model CNNs (MoNet)[11]、GraphSAGE[12]等。
注意力机制
优势之一是它们允许处理不同大小的输入,通过关注输入中最相关的部分来做出决定。self-attention / intra-attention使用注意机制来计算单个序列的表示,不仅能提升RNN和CNN的性能,而且足以用于构建一个更强大的模型,因此本文提出了GAT,具有以下优势:
- 操作效率高,在跨节点对中可并行计算;
- 通过对相邻节点指定任意权值,可应用于不同度的图节点;
- 该模型直接适用于归纳学习问题,包括讲模型推广到完全不可见图的任务。
GAT Architecture
Graph Attentional Layer
输入输出
GA层的输入是一组节点特征,记为 $\mathbf{h}=\left\{\vec{h}_{1}, \vec{h}_{2}, \ldots, \vec{h}_{N}\right\}, \vec{h}_{i} \in \mathbb{R}^{F}$ ,其中 $N$ 是节点的个数,$F$ 是每个节点的特征数。
GA层的输出是一组新的节点特征,记为 $\mathbf{h}^{\prime}=\left\{\vec{h}_{1}^{\prime}, \vec{h}_{2}^{\prime}, \ldots, \vec{h}_{N}^{\prime}\right\}, \vec{h}_{i}^{\prime} \in \mathbb{R}^{F^{\prime}}$,其中节点个数$N$不变,每个节点的特征数可变化为 $F^{\prime}$。
共享线性变换
为了将输入特征转换为高维特征(增维)以获得足够的表达能力,每个节点将经过一个共享的线性变换,该模块的参数用权重矩阵 $\mathbf{W} \in \mathbb{R}^{F^{\prime} \times F}$来表示,对某个节点做线性变换可表示为 $\mathbf{W} \vec{h}_{i} \in \mathbb{R}^{F^{\prime} }$。这是一种常见的特征增强(feature augment)方法。
self-attention 机制
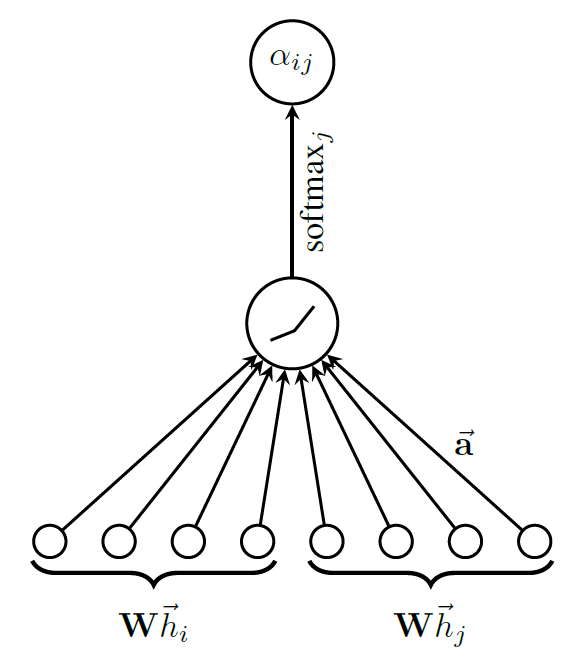
同样是在每个节点间共享self-attention 机制:$\mathbb{R}^{F^{\prime}} \times \mathbb{R}^{F^{\prime}} \rightarrow \mathbb{R}$,可计算节点 $i$ 和 $j$ 之间的attention 系数如下:
该系数表示了节点 $i$ 的特征对节点 $j$ 的重要性。注意机制 $a$ 是一个单层前馈神经网络,用一个权重向量来表示:$\overrightarrow{\mathbf{a}} \in \mathbb{R}^{2 F^{\prime}}$,它把拼接后的长度为2F的高维特征映射到一个实数上,作为注意力系数。
attention 机制分为以下两种:
- Global graph attention:允许每个节点参与其他任意节点的注意力机制,它忽略了所有的图结构信息。
Masked graph attention:只允许邻接节点参与当前节点的注意力机制中,进而引入了图的结构信息。
本文采用Masked graph attention,并且邻接节点是一阶邻接节点(包括节点本身)。
为了使不同节点间的注意力系数易于比较,使用softmax函数对所有对于节点 $i$ 的注意力系数进行归一化:
上述注意力机制,采用共享权重线性变换、Masked self attention 和 LeakyReLU非线性(negative input slope α = 0.2)归一化后的计算公式如下,其中 T表示转置,||表示拼接:
节点特征更新
在得到归一化的注意力系数之后,可以通过对邻接节点特征的线性组合经过一个非线性激活函数来更新节点自身的特征作为输出:
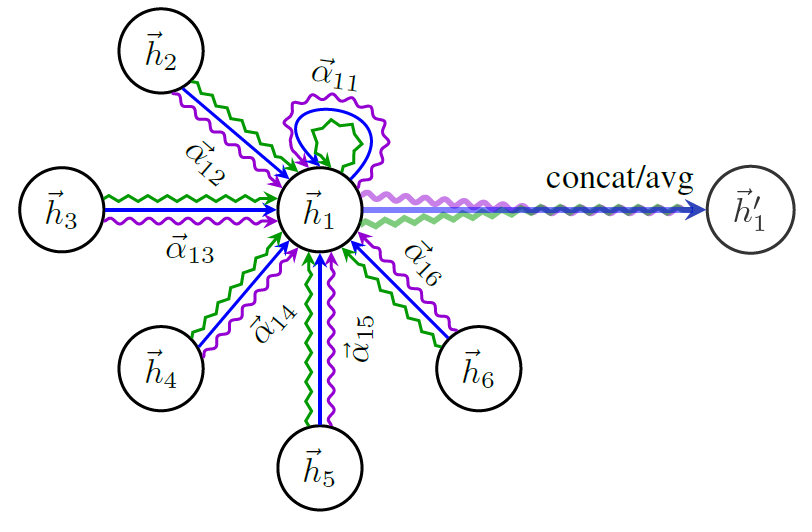
Multi-head attention
为了稳定self-attention的学习过程,本文使用多头注意力机制。具体地,使$K$ 个独立注意力机制根据上式进行变换,得到更新的节点输出特征,然后将$K$ 个特征拼接(concat),得到如下输出特征:
如果我们在最后一层(预测层)使用Multi-head attention mechanism,需要把输出进行平均化,再使用非线性函数(softmax或logistic sigmoid),公式如下:
Multi-head attention mechanism 的示意图如下所示:
Comparisons to Related Work
GA层直接解决了用神经网络处理图结构数据方法中存在的几个问题:
- 计算上高效:自注意力层的操作可以并行化到所有的边,输出特征的计算也可以并行化到所有的节点,multi-head attention 中每一头的计算也可以并行化。
- 与GCNs不同的是,GAT模型允许(隐式地)为同一邻接节点分配不同的重要性,从而实现了模型容量的飞跃;此外,分析学习到的注意力系数可能会在可解释性方面带来一些好处。
- 注意力机制以一种共享的方式应用于图中的所有边,因此它不依赖于预先访问全局图结构或其所有节点的(特征)(这是许多先前技术的限制)。
- 不要求图是无向的,如果 $j$ ->$i$ 不存在,我们只需省去计算$\alpha_{i j}$即可。
- 使得模型能够处理inductive任务,能够在训练中完全看不到的图形上评估模型。
- 无需对节点的重要性进行预先排序
- GAT模型是MoNet的一个特例,但与MoNet相比,GAT模型使用节点特征进行相似性计算,而不是节点的结构属性(这需要预先知道图形结构)。
文章还提出了一个利用稀疏矩阵操作版本的GAT层,降低存储复杂度,并允许在更大的图数据集上执行GAT模型。但由于使用的是rank-2 tensors,它限制了GAT的批处理能力,尤其是对具有多个不同图结构的数据集来说。这也是未来的一项研究工作。
Evaluation
Dataset
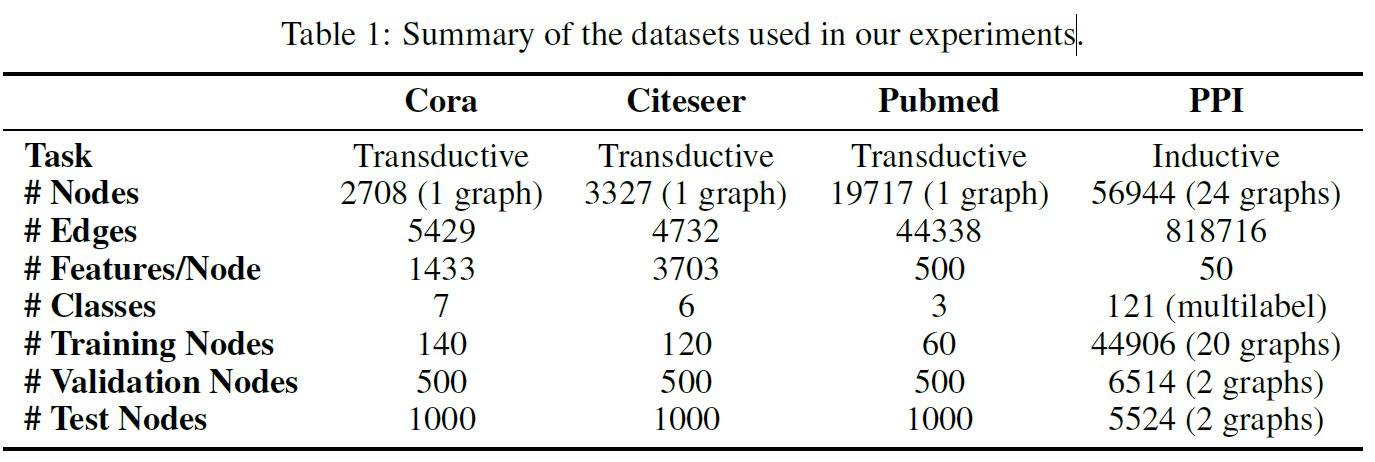
Transductive Learning:
Cora、Citeseer、Pubmed是三个无向固定图结构的数据集,适用于Transductive Learning。每个节点都有一个类别标签,节点特征是词向量表示。每一类用20个节点进行训练,500个节点进行验证,1000个节点进行测试。
Inductive Learning:
protein-protein interaction (PPI) 数据集包含不同人类组织对应的不同图结构,适用于Inductive Learning。用其中20个图进行训练,2个图进行验证,2个图进行测试。测试图在训练过程中是完全没有被观察到过的。
State-of-the-art Methods
Transductive Learning:
label propagation (LP)、semi-supervised embedding (SemiEmb)、manifold regularization (ManiReg)、skip-gram based graph embeddings (Deep- Walk)、iterative classification algorithm (ICA)、Planetoid、GCNs、graph convolutional models utilising higher-order Chebyshev filters、MoNet model
Inductive Learning:
GraphSAGE-GCN、GraphSAGE-mean、GraphSAGE-LSTM、GraphSAGE-pool
另外,对于这两个任务,还提供了每个节点共享多层感知器(MLP)分类器的性能(它完全不包含图结构)。
Experimental Setup
Transductive Learning:
对于前两个数据集,建立两层GAT模型,第一层$K=8$, $F’=8$,输出特征数为64,经过exponential linear unit (ELU) 非线性函数;第二层用于分类,$K=1$,采用softmax激活函数。为了解决训练集较小的问题,正则化在模型中得到了广泛的应用。在训练中,我们应用L2正则化($lamda=0.0005$),dropout($p=0.6$)。
对于第三个数据集,改变第一层$K=8$,L2正则化($lamda=0.001$),其他结构和参数保持不变。
Inductive Learning:
采用三层GAT模型,前两层$K=4$,$F’=256$,输出特征为1024,经过ELU 非线性函数;最后一层用于分类,$K=6$,$F’=121$,对输出特征进行平均并经过一个logistic sigmoid 激活函数。由于训练集充足,未采用L2正则化和dropout,但使用了skip connections挑过了中间的注意力层。
所有模型采用Glorot初始化,采用Adam SGD optimizer(Pubmed数据集学习率取0.01,其余数据集学习率为0.005),最小化交叉熵损失,使用早期停止策略。
Results
实验结果如下表所示:

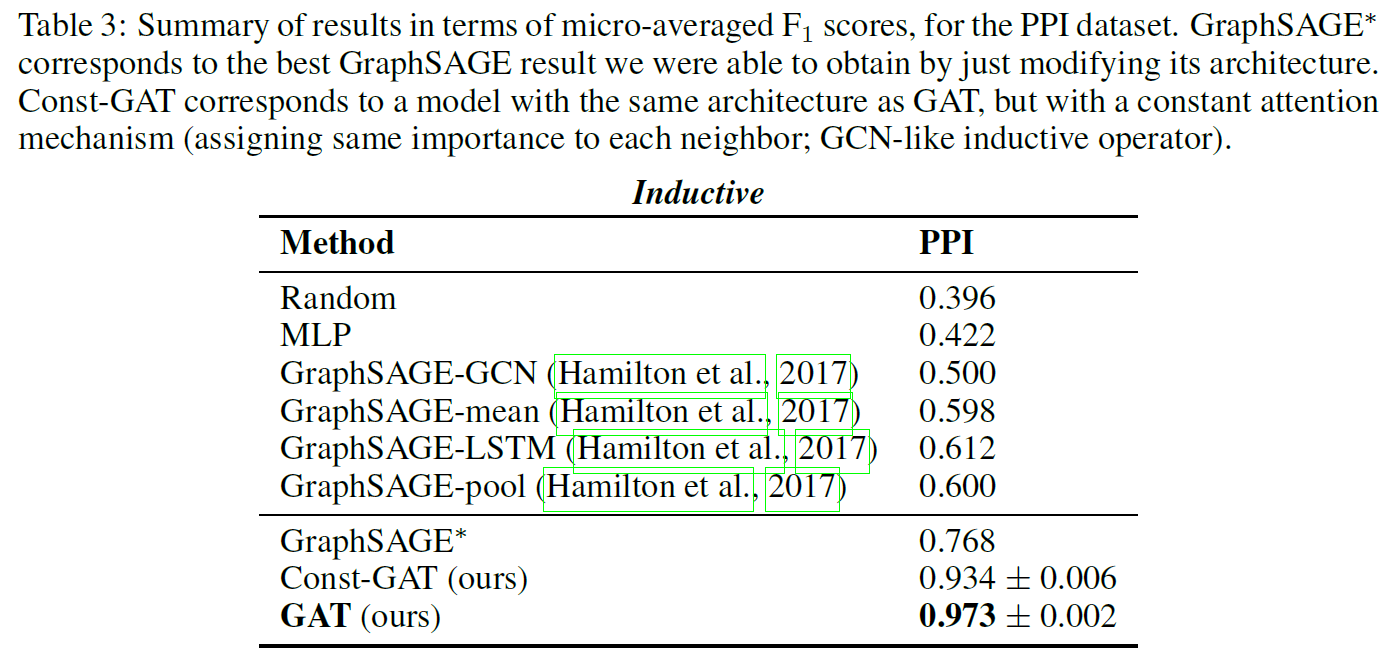
- 跟GCNs相比,GAT模型在Cora和Citeseer数据集上精度分别提高了1.5%和1.6%,这表明对邻接节点分配不同的注意力系数是有益的。
- 跟GraphSAGE相比,GAT在PPI数据集上精度提高了20.5%,说明了GAT模型在inductive任务上的潜力,以及对不同邻接节点分配不同注意力系数的有效性。
GAT模型在Cora数据集上的分类结果可视化如下:

Conclusion
本文提出了图注意力网络(GATs),这是一种新型的利用masked self-attention 的卷积式神经网络,它能够处理图结构的数据,具有计算简洁、允许不同权重的邻接结点、不依赖于整个图结构等优势,可以处理谱方法的诸多缺陷,在各数据集上获得了最佳的性能。
Future Works
有几个潜在的可改进和扩展GATs的未来工作,如克服前述只能处理一个批次数据的实际问题,使得模型能够处理更大的批次数据。另外一个特别有趣的研究方向是利用注意力机制对模型的可解释性进行深入分析。最后,扩展模型以包含边的特征(可能表示节点之间的关系)将允许我们处理更多种问题。
Understanding
- GAT与GCN本质思想都是将邻接节点的特征聚合到中心节点上(aggregate 运算),利用图上的local stationary 学习新的节点特征,但是两者的实现思路和方法是不同的,GCN是利用图的具体结构,构造拉普拉斯矩阵进行local convolution,而GAT是利用节点之间的相关性,构造attention系数,并且该系数只与节点的特征有关,和图的结构无关。因此GAT的学习能力会更强。
- GAT采用逐点运算,对于有向图来说,可以根据需要选择计算节点之间的attention系数,摆脱了GCN中的拉普拉斯矩阵的束缚。并且,注意力系数也仅与节点特征相关,与图结构无关,因此改变图的结构对GAT的影响不大,只需要改变邻接节点个数,重新计算即可,这也是能胜任inductive学习的原因所在。
Reference
- Paolo Frasconi, Marco Gori, and Alessandro Sperduti. A general framework for adaptive processing
of data structures. IEEE transactions on Neural Networks, 9(5):768–786, 1998.- A. Sperduti and A. Starita. Supervised neural networks for the classification of structures. Trans.
Neur. Netw., 8(3):714–735, May 1997. ISSN 1045-9227. doi: 10.1109/72.572108.- Marco Gori, Gabriele Monfardini, and Franco Scarselli. A new model for learning in graph domains. In IEEE International Joint Conference on Neural Networks, pp. 729734, 2005.
- Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini.
The graph neural network model. IEEE Transactions on Neural Networks, 20(1):61–80, 2009.- Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. Gated graph sequence neural
networks. International Conference on Learning Representations (ICLR), 2016.- Kyunghyun Cho, Bart Van Merri¨enboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally
connected networks on graphs. International Conference on Learning Representations (ICLR),
2014.- Mikael Henaff, Joan Bruna, and Yann LeCun. Deep convolutional networks on graph-structured
data. arXiv preprint arXiv:1506.05163, 2015.- Micha¨el Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems, pp. 3844–3852, 2016.
- Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. International Conference on Learning Representations (ICLR), 2017.
- Federico Monti, Davide Boscaini, Jonathan Masci, Emanuele Rodol`a, Jan Svoboda, and Michael M Bronstein. Geometric deep learning on graphs and manifolds using mixture model cnns. arXiv preprint arXiv:1611.08402, 2016.
- William L Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large
graphs. Neural Information Processing Systems (NIPS), 2017.