Handling Variable-Dimensional Time Series with Graph Neural Networks
1-MOTIVATION
物联网(IoT)技术的一些应用涉及从多个传感器捕获数据,从而产生多传感器时间序列。
现有的基于神经网络(NN)的多变量时间序列建模方法假设传感器的输入维数(即传感器的数量)是固定的。
在实际应用中,例如手机、穿戴设备、工业设备等,这些相同设备的不同实例安装的传感器组合通常是不同的,因此无论下游任务是预测还是分类,模型在设计时就需要考虑不同(可变)的输入维度,以构造一个针对某一设备来说较为通用的模型架构。
2-INTRODUCTION
背景
由于IoT的快速发展,设备范围的不断扩大,多传感器时间序列数据无处不在并且快速增长。深度学习方法已经成功地应用于多元时间序列预测、分类、异常检测和剩余有用寿命估计。
假设与矛盾
大多数现有的对多变量时间序列数据建模的方法假设固定维的时间序列作为输入,这在许多实际情况下,这种假设可能并不成立。例如,在学习活动识别模型时,由于穿戴设备实例的不同,不同人的时间序列可能涉及到不同数量的可用传感器(如加速度计、陀螺仪、磁力仪)。类似地,设备运行状况监控模型也需要处理来自不同实例设备的数据,这些实例上安装了不同的传感器(比如温度、振动和压力)。
针对场景
在这项工作中,作者考虑了由同一底层动力系统的不同实例(例如在活动识别中的人)生成多个不同传感器组合的多元时间序列分析问题。即网络的输入维度是不确定的,(但不超过某个最大上限)。
方法优势
提出的模型在zero-shot (测试集中可用传感器的组合与训练集中的组合都不相同)和fine-tuning (训练集中包含有少量与测试实例相同组合的样本可用于微调)两个设定实验下性能优于普通NN模型,并且通过ablation study验证了模型各个组成成分的有效性。
3-RELATED WORKS
把传感器个数的变化看作是缺失值,常用的处理时间序列实例中传感器丢失的方法是根据其他实例中传感器可用时的统计数据,为该缺失传感器假定一个常数值(通常是均值)。
- 但是随着测试实例中传感器丢失百分比的增加,该方法的性能会迅速下降。
仍然是把传感器个数的变化看作是缺失值,一般使用平滑、插值和样条等数据填充方法。
- 由于它们依赖于时间序列中每个维度至少有一个可用值的情况,因此不适用于整条时间序列缺失的问题设置。
针对不同的传感器组合,为每一种可能的组合训练不同结构和参数的网络。
- 当可能组合的数量呈指数级增长时,网络扩展困难;
- 假设每一种组合都有足够的训练数据可用;
- 且不同模型训练时不保留任何跨组合的知识。
以上相关方法都有一定的缺陷,因此作者在GNN、transfer-learning、meta-learning的启发下,提出了一种新的神经网络结构,适用于zero-shot 和fine-tuning迁移学习,能够实现在测试时对多变量时间序列进行鲁棒的推理,且这些多变量时间序列中的有效维度(即可用的传感器组合)是未知的。
4-PROBLEM DEFINITION
对本问题场景进行数学上的描述,对于符号达成以下共识:
- 考虑一个训练集$\mathcal{D}=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}_{i=1}^{N}$ ,具有$N$个多变量时间序列 $\mathbf{x}_{i} \in \mathcal{X}$ 和对应的标签 $y_i \in \mathcal{Y}$。
- 每个时间序列 $\mathbf{x}_{i}=\left\{\mathbf{x}_{i}^{t}\right\}_{t=1}^{T_{i}}$的长度都为 $T_i\in\mathcal{T}$。
- $\mathcal{S}$表示包含所有传感器的集合,共$d$维(即变量最大维度为$d$);$\mathcal{S}_i \subseteq \mathcal{S}$表示不同的传感器组合,其下标 $i$与 $\mathbf{x}_{i}$ 中的下标对应,表示当前组合包含的可用传感器共$d_i$维,$1 \leq d_{i} \leq d$。
- 对于某个时刻$t$来说,$\mathbf{x}_{i}^{t}$ 是 一个 $d_i$ 维的向量,即 $\mathbf{x}_{i}^{t} \in \mathbb{R}^{d_{i}}$。
- 下游任务的目标是,学习到 $\mathcal{X}$ 与 $\mathcal{Y}$ 之间的映射关系:$f: \mathcal{X} \rightarrow \mathcal{Y}$。
5-APPROACH
作者提出一个新的基于GNN的时间序列分析模型,利用神经网络架构(GRU,当然LSTM也可)与两个全新的模块:
core dynamics module——用于对数据的时序特性进行建模;
conditioning module——基于不同的传感器组合,利用GNN学习各可用传感器之间的信息聚合关系,并生产一个“conditioning vector”作为附加输入传递至core dynamic module,对时序特性的建模进行定制化调整。
模型总体架构示意图如下所示:
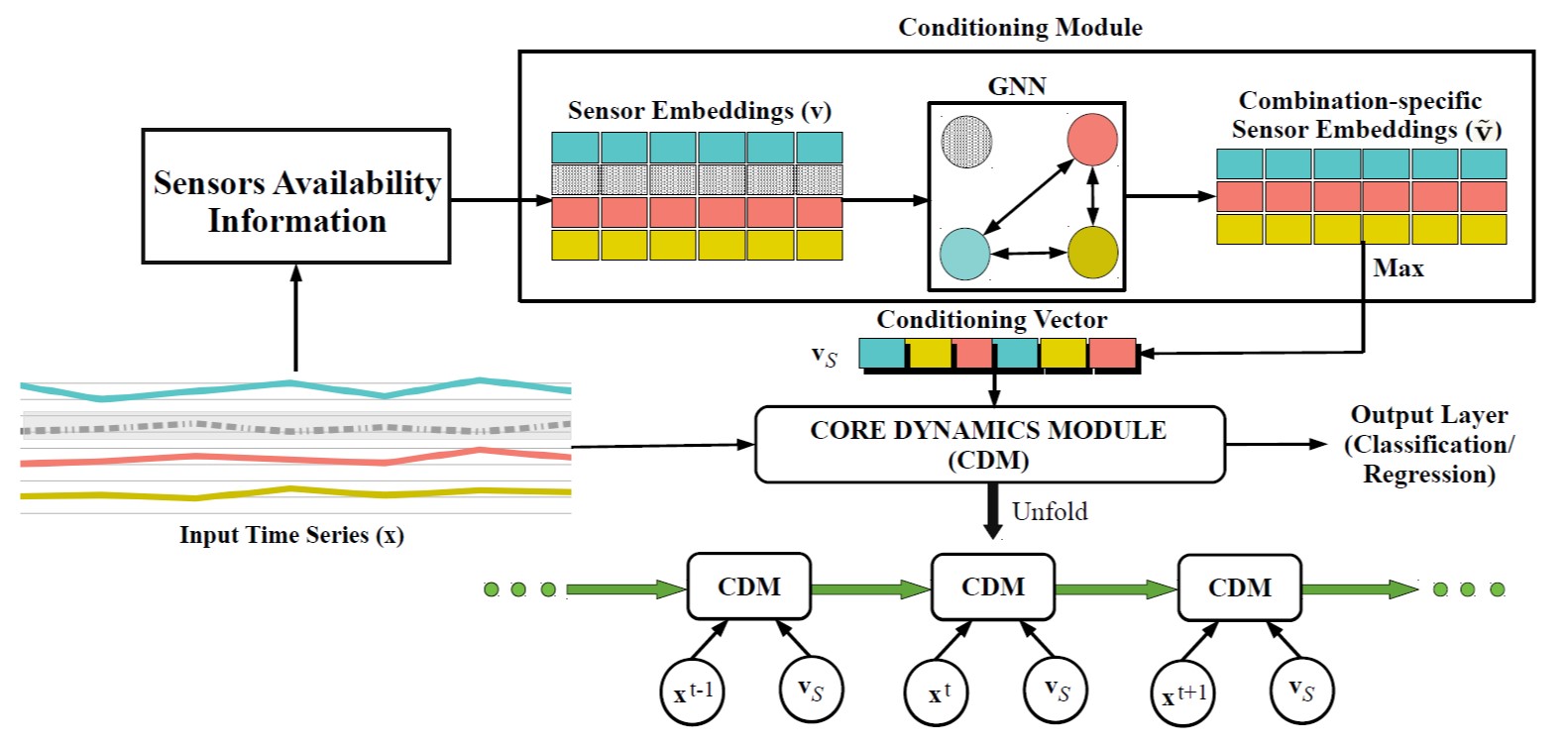
Data Processing
Details
首先确定最大变量维度d,所有变量组合的维度$1 \leq d{i} \leq d$。如左下角的Input Time Series(x) 所示,对第二维缺失传感器数值的维度进行mean-imputed,即该传感器在其他实例中可用时的平均值,预处理后的多变量时序数据$\mathbf{x}{i}$中每个时刻的输入都是一个d维向量。
这个操作实质上是为了能把等长维度的数据喂给GRU网络作为输入。
Conditioning Module
Details
在图表示学习的启发下,将每一个可用的传感器看作一个结点(vertices)。两个结点之间的关系定义为边(edges)。对应于包含全部传感器的组合$\mathcal{S}$,考虑用图$\mathcal{G}(\mathcal{V}, \mathcal{E})$来表示,每个$s\in\mathcal{S}$ 对应一个结点$v_s\in \mathcal{V}$,每个结点$v_s$的邻节点用 表示。
每个传感器 $s \in \mathcal{S}$ 与一个可学习的embeding vector(嵌入向量) $v_s\in \mathbb{R}^{d_{s}}$ 相关联。
对于一个特定的多个传感器的组合$\mathcal{S}_i$,可用的传感器对应的结点被激活,图中每两个active结点之间连成的边也被为激活(fullly-connected)。因此,就如结构图上GNN框中的三个彩色结点所示,这三个结点以及它们两两之间的边都是激活的。
对于不同的组合都有一个确定的图结构,基于图结构我们构造结点更新网络及边更新网络:
node-specific feed-forward network(结点前馈网络)& edge-specific feed-forward network(边前馈网络)
结点的更新体现了相邻结点对当前结点的聚合作用,具体的,对于任意一个active node$v_k$,对应的结点向量$\mathbf{v}_{k}$的更新公式如下:
其中,$\mathbf{V}_{k l}$表示所有与$v_k$相连的结点$v_{l} \in \mathcal{N}_{\mathcal{G}}\left(v_{k}\right)$对$v_k$产生的作用。
$\tilde{\mathbf{V}}_{k}$表示$v_k$在聚合了所有$\mathbf{V}_{k l}$对她的影响之后,对自身结点的一个更新。
$\theta _e$和$\theta _n$分别为$f_e$和$f_n$的可学习参数,简单来说,$f_e$将邻结点信息传递到待更新结点,$f_n$利用邻结点的聚合信息更新相应结点。
另外,$fn$和$fe$在图中所有的结点和边上共享权重系数,也就是说这两个网络训练的不是特定点之间或特定边上的更新方式,而是整个图通用的更新方式。
最后根据更新后的各结点向量得到一个 conditioning vector
注意,最大化操作原理同卷积网络中的池化操作,也可用平均值代替,相当于卷积网络中的平均池化,但经过作者实验,发现最大池化效果要优于平均池化,因此采用对$\tilde{\mathbf{V}}_{k}$的每一个维度取最大值操作,得到最终的conditioning vector。
本模块采用GNN的优势在于,它学习到的是一个通用的所有结点之间的聚合关系,因此不仅可以处理在训练中出现过的组合,在测试时,可以处理训练集中见过的变量组合之外的unseen组合,从而提高了对组合处理的泛化能力,这也是可以应对zero-shot的本质原因。
Core Dynamics Module
Details
- Core Dynamics Module 包含一个gated RNN模型,文中采用GRU,当然也可以用LSTM等。
- 输入时固定维度的多变量时序数据(由于在数据预处理中,我们将缺失的变量用常量进行了填补,并记填补后的输入为$\tilde{\mathbf{x}}_{i}$)。
- 与普通的模型输入不同的是,在本模块中,需要把时序数据$\tilde{\mathbf{x}}_{i}$和上面模块中得到的conditioning vector 拼接起来(维度扩展)一起输入GRU进行训练,并与上一时刻的特征向量一起,往下一个时刻进行信息传输,具体公式为:
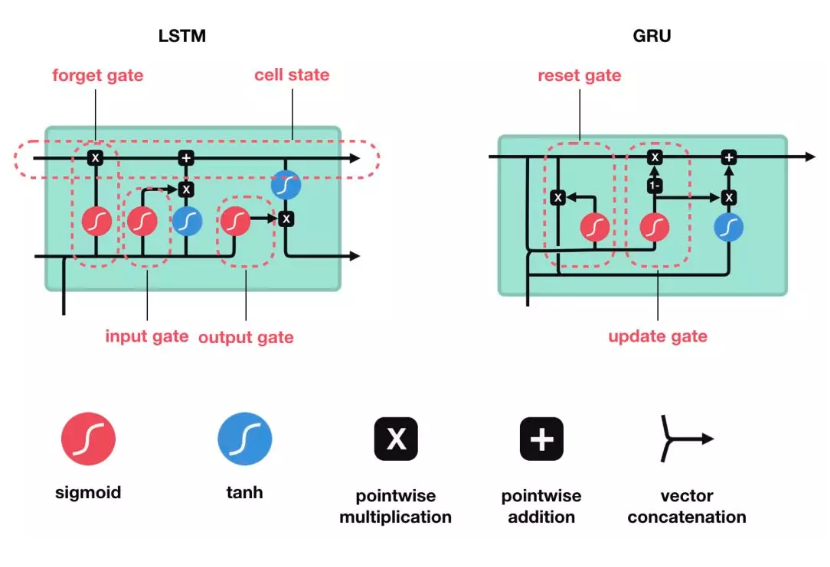
- 在最后一个时刻,得到模型输出的特征向量$\mathbf{z}_{i}^{T_i}$,预测的输出根据不同的下游任务进行构造和确定:附上LSTM和GRU的结构图作为参考:
Training Rules
- 整个模型通过随机梯度下降(SGD)以end-to-end的形式进行整体的训练。
损失函数:
- 分类:
- 预测:
注意:该模型参数学习的方式为mini-batch SGD,是在每个mini-batch内输入具有相同变量组合的时间序列进行训练,而整个batch包含多种不同的变量组合。
6-EXPERIMENT
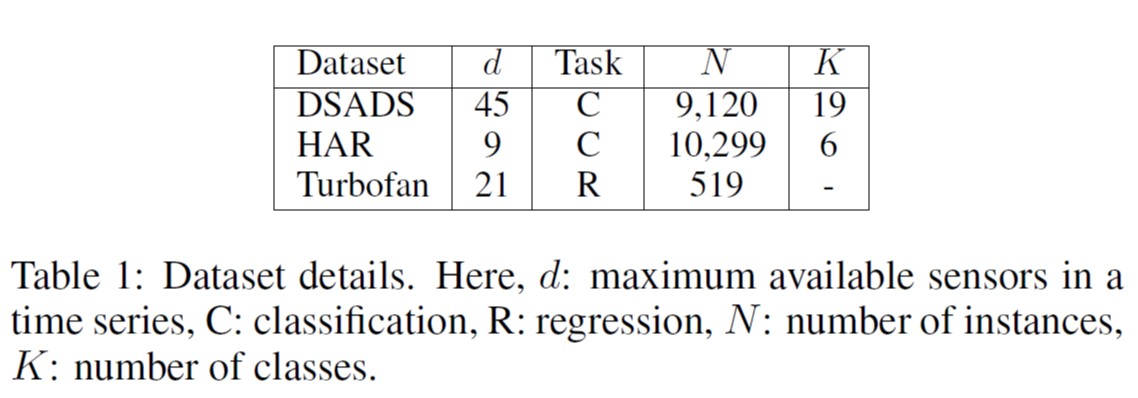
Dataset
- DSADS
- HAR
- Turbofan
Experimental Setup
- Zero-shot setting:把一部分变量组合包含的数据作为训练数据,除训练集外剩下所有unseen的组合作为测试数据,直接使用训练好的网络进行推理。
- Fine-tuning setting:把一部分变量组合包含的数据作为训练数据,使用除训练集外的一部分与测试集相同变量组合的带标记数据来微调网络参数,用剩下的测试数据进行测试。
- $f_{t r}$和$f_{t e}$表示训练和测试过程中每个时间序列不可用传感器的比例,把训练时的比例记为$f_{t r}=\{0.25,0.4\}$,测试时的比例记为$f_{t e}=\{0.1,0.25,0.4,0.5\}$
- 对于所有数据集,40%用于训练,10%用于验证,10%用于微调(在zero-shot情况下忽略),其余40%用于测试。
- 评价指标:分别使用分类错误率和均方根误差(RMSE)作为分类和回归任务的性能指标。
Hyperparameters Used
- core dynamics module 由三层GRU构成,每层GRU各有128个单元,每个结点的嵌入向量维度为d/2。
- mini-batch在训练时和fine-tuning时的大小分别为64和32,所有前馈层之后都有0.2的dropout用于正则化,训练时采用最大150 epoch,微调时采用最大50 epoch。
- 使用无动量的vanilla SGD以5e-4的学习率来更新传感器嵌入向量,用Adam以1e-4的学习率来更新的其他层的学习速率。(由于active 结点在每一个mini-batch中都会随着可用传感器组合的变化而变化,我们发现使用vanilla SGD来更新传感器向量是有用的,然而如果我们加入动量,非active结点的向量也会得到更新;另一方面,在所有变量组合和mini-batch共享的GNN和核心模块,都受益于momentum,因此Adam用于更新它们的参数。)
Baselines Considered
- GRU-CM (GRU with GNNbased conditioning module):文章提出的模型
- GRU:在缺失传感器中填充均值,相当于GRU-CM模型去掉了conditioning module,只有时序模块,因此不会给GRU提供额外的条件向量信号。
- GRU-A(GRU with All Sensors Available):该模型对于所有的训练和测试实例,可使用所有的传感器的数值,(即无传感器缺失),训练超参数与GRU-CM相同,旨在找出模型精度的一个上届。
- GRU-SE(GRU with Maxpool over Sensor Embeddings):这是一项在GRU-CM上的消融研究,忽略了结点更新和边更新所涉及的两个步骤,将最大池化操作直接应用于原始的传感器嵌入向量,无需通过GNNs进行组合特异性处理。换句话说,特定组合的active 结点彼此之间不交换消息以适应特定的传感器组合。
- 注意,另一个对比模型可能是为每个维度学习一个单独的模型,但这在计算上很昂贵,所需的资源将随着时间序列的维度增长。此外,这样的方法将不能有效地捕获多维间的相关性。
Result and Observations
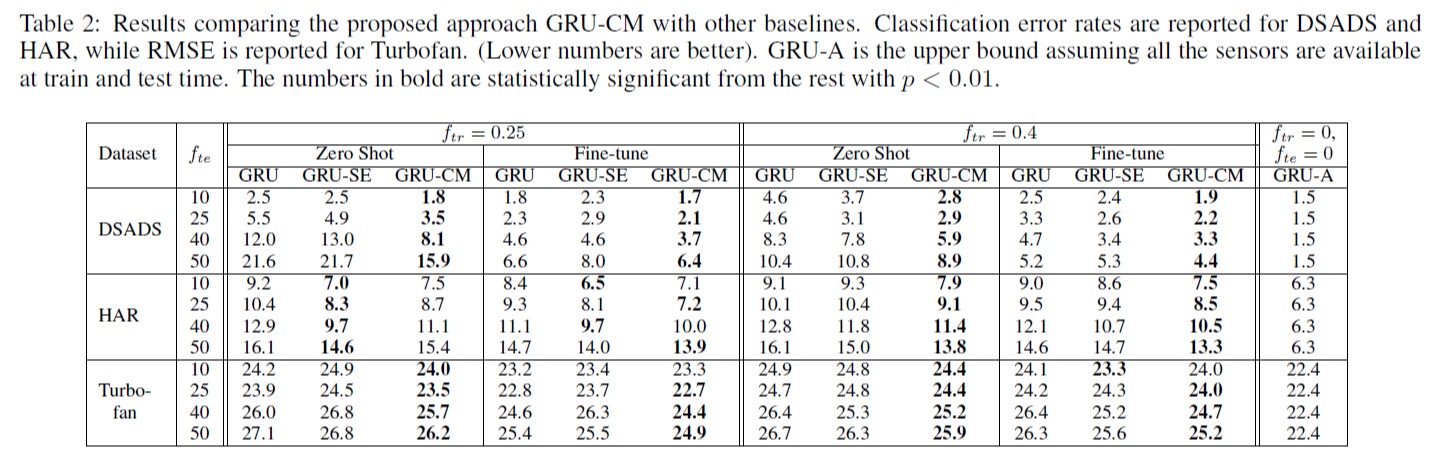
- 在zero-shot和微调测试场景中,GRU-CM在三个数据集上的表现都优于普通的GRU。换句话说,在大多数情况下,GRU-CM能够显著缩小GRU-A和GRU之间的差距,证明其鲁棒性可以适应于不可见的传感器组合。
- 在zero-shot情形下,GRU-CM要明显优于GRU,fine-tuning也能大大提升GRU和GRU-CM的性能,而相比之下,GRU-CM在fine-tuning数据量不多的时候,更能快速适应,比GRU精度更高。
- 随着测试时不可用传感器的比例增加,GRU和GRU-CM的性能都会下降。然而,与GRU相比,GRU-CM性能下降得更为缓慢,体现了conditioning module的优势。
- 在与GRU-SE比较的消融实验中,在大多数情况下,GRU-CM的效果优于GRU-SE。此外,GRU-SE有时表现不如普通的GRU。这些观察结果证明了在可用传感器之间传递消息以提供更好的条件向量的重要性。
Side Experiment
在本实验中,fine-tuning的数据不是来自于测试集,而是取训练集中与测试集里传感器组合有高度重合部分的样本进行微调,并把微调结果和zero-shot情形进行对比。
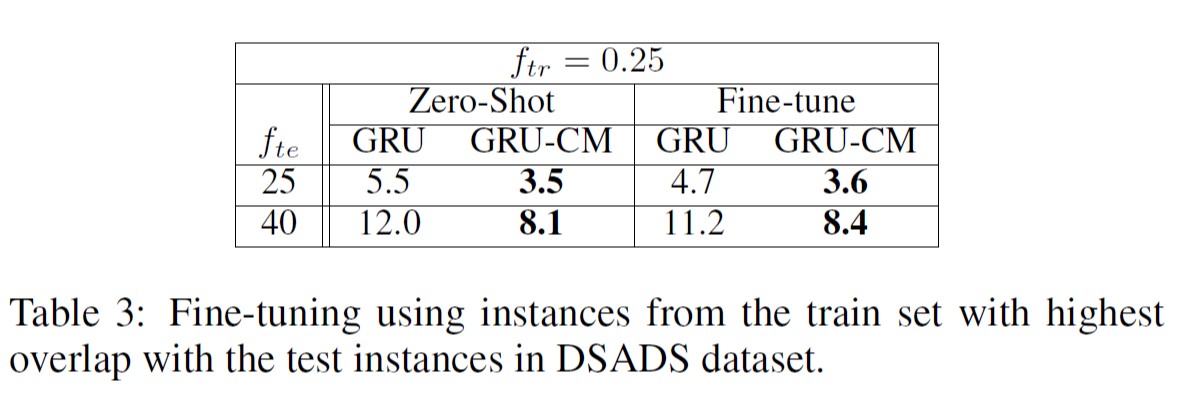
- 从对比结果可以看出,这种微调方式下,与原来的zero-shot相比,GRU和GRU-CM的结果都有所改善,但GRU-CM的表现仍好于GRU。这进一步突出了GRU-CM适应新传感器组合的能力,甚至比让GRU针对特定实例进行微调更好。
7-IDEA
- 在GNN中加入注意力机制
- 在用高度重叠实例进行fine-tuning时可考虑找多个高重叠度的实例进行集成学习进行互补。